System metrics with Prometheus#
Package Security Manager (On-prem) system performance can be monitored to understand system health, evaluate network traffic, and detect issues. Each of Package Security Manager’s services expose a set of metrics that can be visualized using the built-in Prometheus expression browser. Metrics are provided in OpenMetrics (Prometheus) format.
Accessing Prometheus#
In your web browser, append /prometheus/ to your Package Security Manager fully qualified domain name (FQDN). For example: https://<FQDN>.com/prometheus/
Creating graphs for metrics#
Prometheus uses a built-in expression browser for time series visualizations of system metrics.
To create system metric graphs in Prometheus:
Enter the name of an expression you want to view in the search box.
Select your expression from the list that appears.
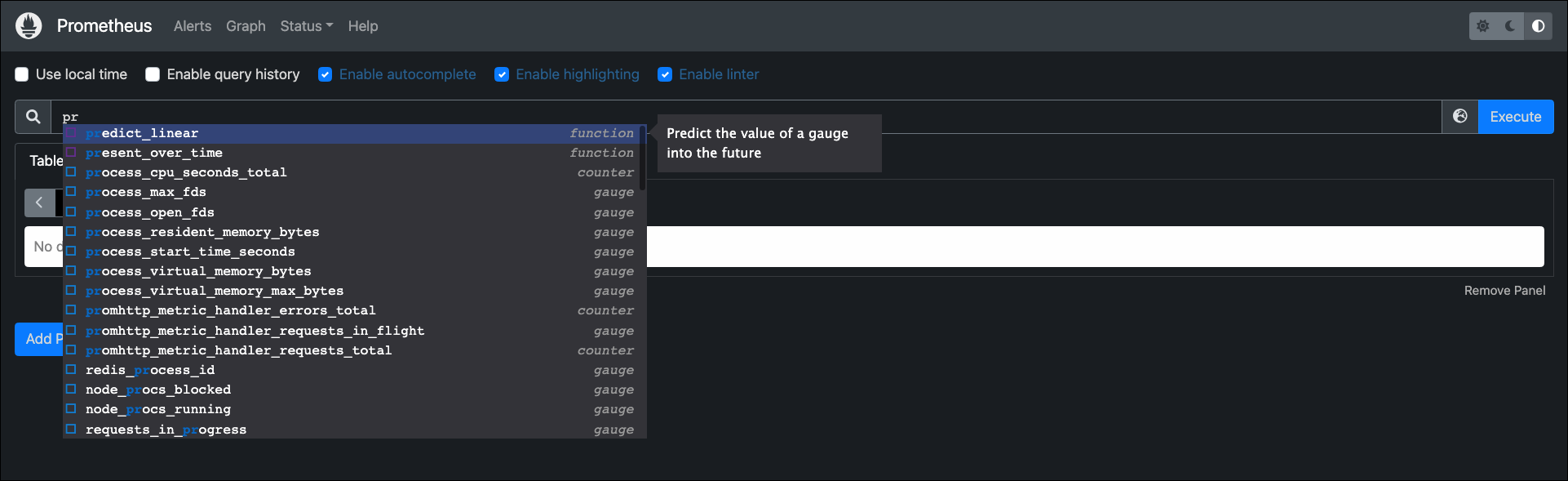
Click Execute.
Select the Graph tab.
The graph is populated by the selected metric, and a console readout appears below it.
Tip
To isolate a specific resource, select it from the legend below the graph.
Popular metrics#
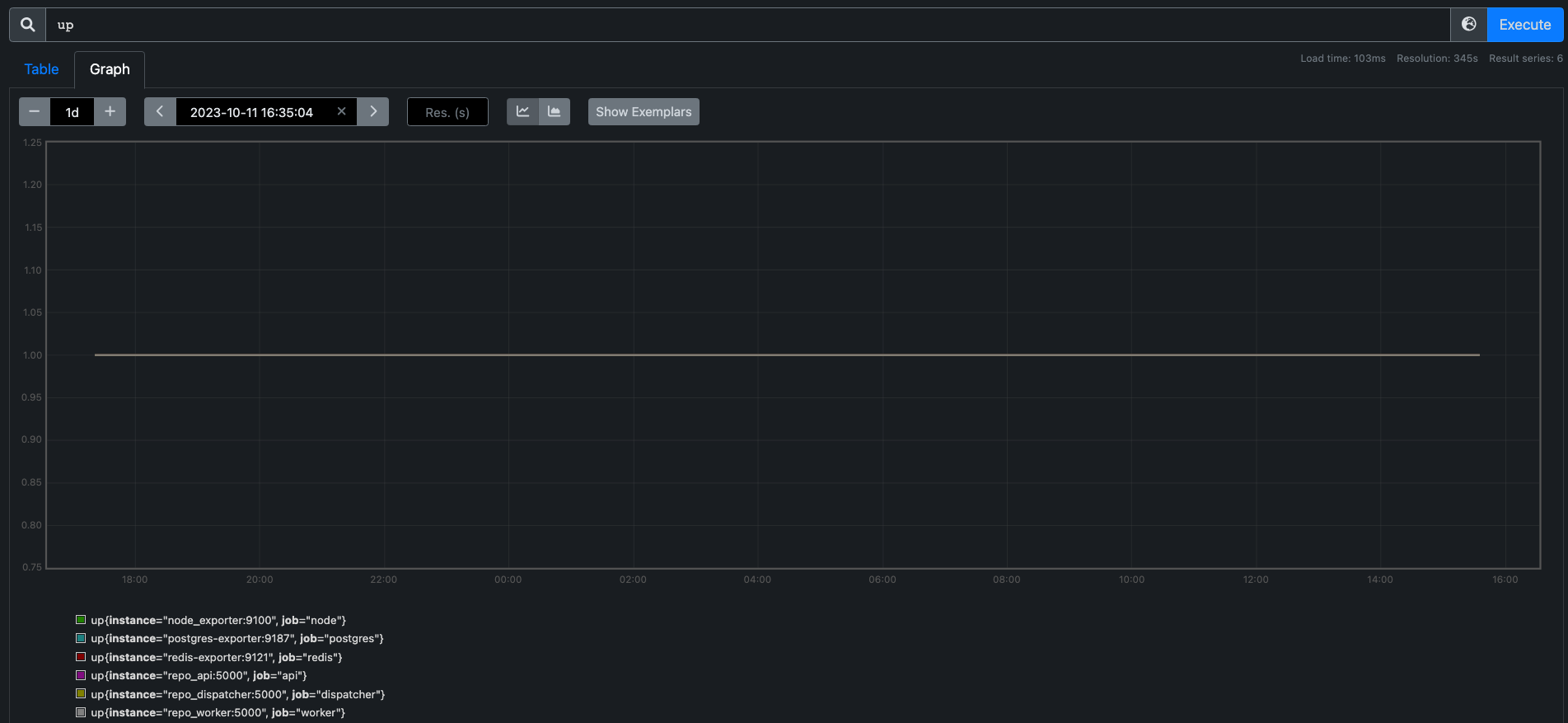
up#
The up time metric tells you if your instance is running.
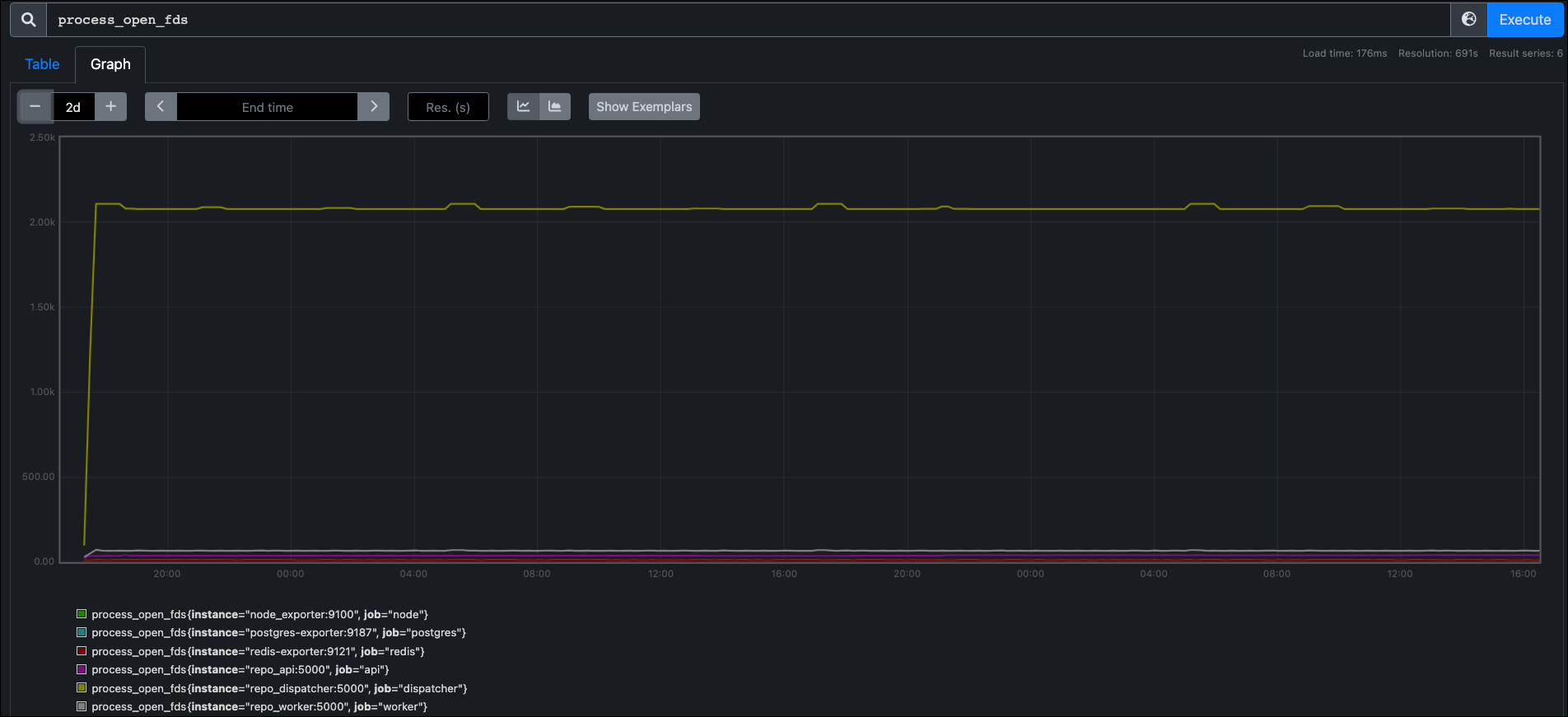
process_open_fds#
The process_open_fds metric counts the number of files in the /proc/PID/fd directory.
This tells you how many regular files, sockets, pseudo terminals, etc. you currently have open.
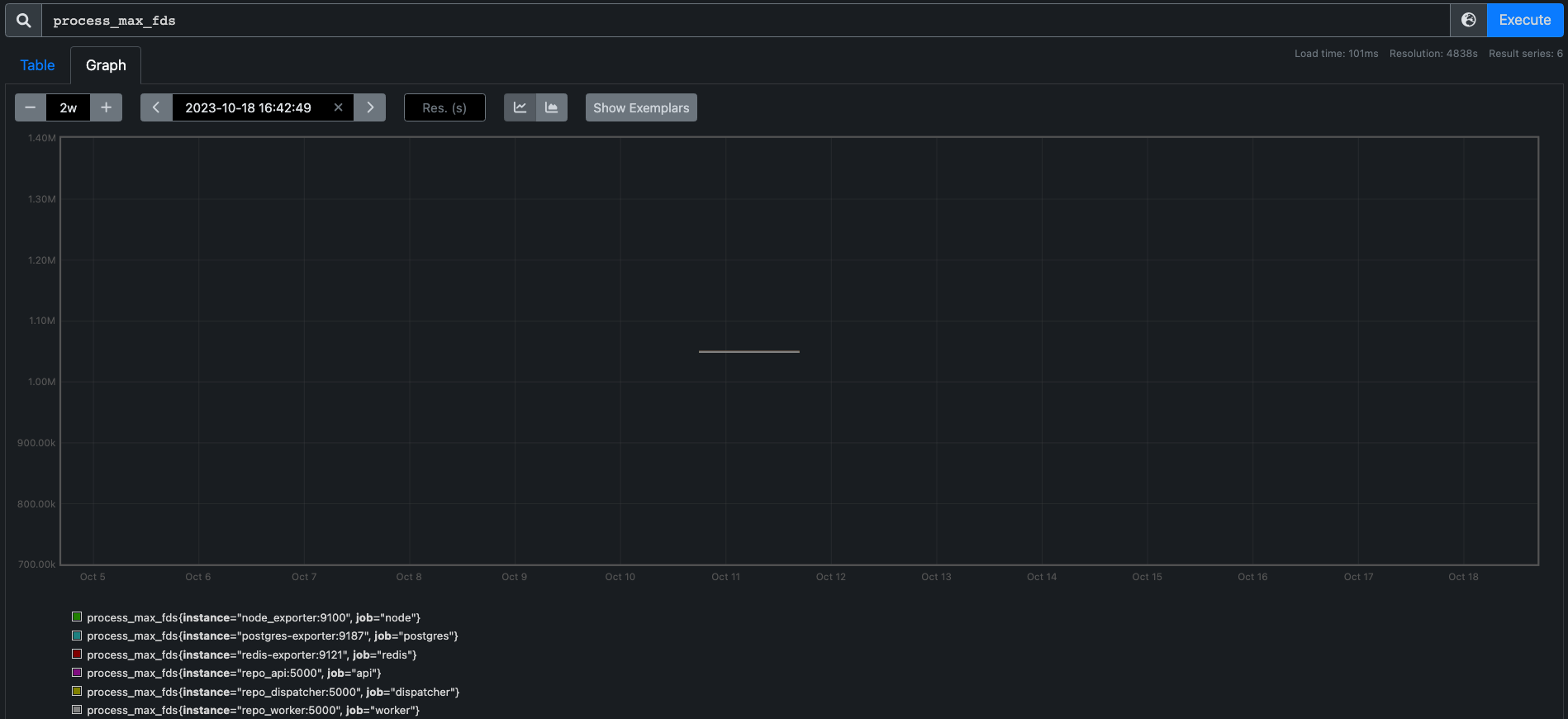
process_max_fds#
The process_max_fds metric reads /proc/<PID>/limits and uses the Soft Limit from the Max Open Files row.
Note
/limits lists both soft and hard limits. The soft limit is the value the kernel enforces for the corresponding resource, while the hard limit acts as the ceiling for the soft limit.
Setting a file limit alert#
Using the two metrics above, process_open_fds and process_max_fds, you can write an alert to warn you when a process hits 80% of the limit:
groups:
- name: example
rules:
- alert: ProcessNearFDLimits
expr: process_open_fds / process_max_fds > 0.8
for: 10m